Programm
- Verschiedene Abschnitte in denen verschiedene Konstrukte vorgestellt werden
- Am Ende sollen alle in der Lage sein, eine Webservice mit
rocketzu programmieren, was aber für heute kein muss ist - Jeder Abschnitt enthält eine Übungsaufgabe, die zunächst alleine/in der Gruppe und dann gemeinsam gelöst werden kann
Zu mir
- Arbeite und lebe in Leipzig
- Engagiere mich im Hackspace des Dezentrale eV, die Projekte bspw. anbietet wie
- Hardware For Future
- Chaos macht Schule
- Freifunk
- Programmierrunde
- Elektronikrunde
- Techniksprechstunde
- Programmiere hauptsächlich Python, C, Java
- Eher als Hobby Micropython, Erlang
- Rust habe ich vor 2,3 Jahren eher aus Interesse angefangen und konnte es irgendwann auch auf Arbeit einsetzen
- Auf Linux unterwegs seit fast 20 Jahren
- Rückfragen nach dem Workshop an mich
- Workshop Unterlagen veröffentliche ich auf github
Wozu wir heute nicht kommen werden
- Große Ausflüge in die Dokumentation
- Feature Verwaltung
- Makro-Programmierung
- C-Anbindung
Vorstellungsrunde
- Programmiert ihr im Alltag oder schreibt ihr eher Skripte?
- Womit programmiert ihr euren Alltag?
- Was habt ihr von Rust bisher gehört?
- Was ist eure Motivation Rust zu lernen?
Was ist Rust eigentlich?
- Programmiersprache für verschiedene Plattformen wie x86, ARM, Webassembly für den Browser
- Sprache wird kompiliert und nicht interpretiert
- Kompiler heißt
rustc, der auf LLVM basiert, GCC Frontend auch möglich - Paketmanager heißt
cargo - Bibliotheken/Anwendungen sind in
cratesorganisiert - Weiterentwicklung wird von der Rust Foundation organsiert, Gründer waren neben Mozilla, u.a. Amazon, Google & Huawei
Ein kurze Geschichte
Es war einmal ein Browserhersteller namens Mozilla, der hatte viel C/C++ Code.
Mehrkernprozessoren wurden immer verbreiteter und paralelle Code-Ausführung wurde immer wichtiger.
Parallele Code-Ausführung für C/C++ ist aber aufwendig, kompliziert und es gilt vieles zu bedenken.
Tools gibt es zur genüge für Code-Analyse, aber viele Dinge können davon auch nicht abgefangen werden.
Menschen produzieren unvermeidlich Programmierfehler. Programme stürzen ab und verursachen Sicherheitslücken.
Um das zuvermeiden gab es keine sinnvolle Programmiersprache.
Was macht die Sprache aus?
- systemnah
- bietet ein Ausführungsgeschwindigkeiten und Optimierungen wie C/C++
- in Zukunft auch im Linux Kernel vertreten
- durch verschiedene Sprachkonstrukte wird sicherer Code produziert
- Nutzt viele Konzepte aus bereits existierenden Sprachen
- Starke Typisierung
- Abstraction by Zero Cost (
Templates,Generics)- Einführung von komplexen Abstraktionen
- Kombinationen von verschiedenen abhängigen Implementierungen
- Ausführung von nur benötigten Bestandteilen der Abstraktionen
- Funktionale Ansätze
- Jede Methode ist eine Funktion
- Map/Reduce
- Keine Objektorientiertung, stattdessen Traits und Implementierungen
- Defintion eines gemeinsamen Verhaltens
- Traits werden durch Implementierungen für Typen umgesetzt
- Pointer und Referenzen
- Explizite Deklaration von unsicheren Bereichen (
unsafe) für die Kompatiblität zu C-Implementierungen
- Implizite Speicherverwaltung
- Keine Garbage Colleciton wie
golang,JavaoderC# - Viele Operationen finden nur auf dem Stack statt
- Variablen sind bei der Deklaration standardmäßig nicht veränderlich
- Keine Garbage Colleciton wie
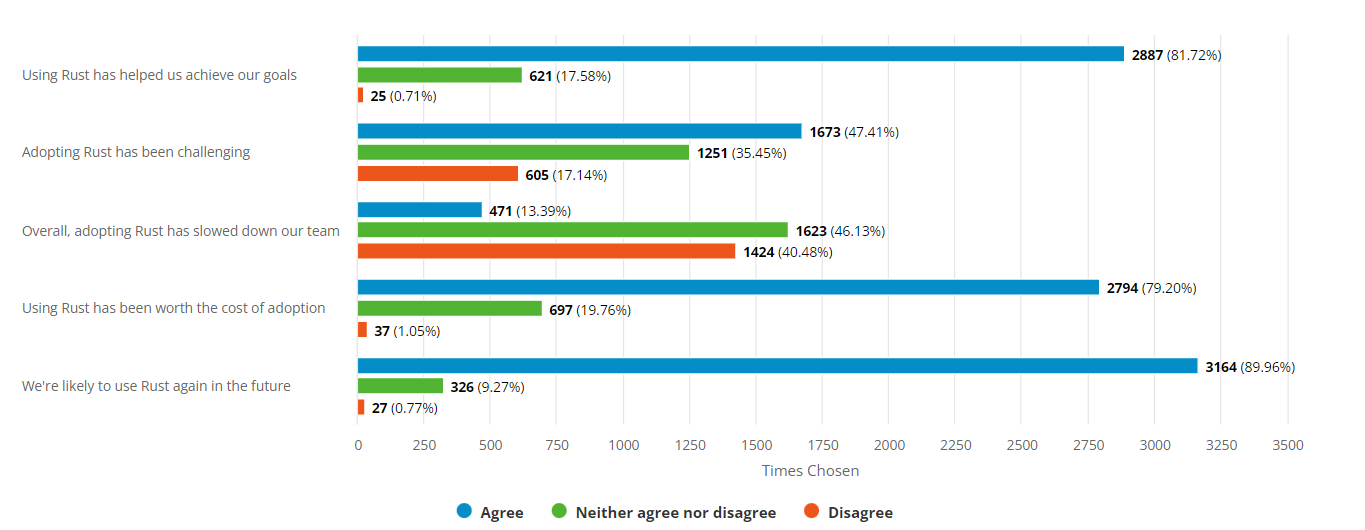
- Befragung für 2021
Sicherheit durch Ausdruck
- Ownership-Konzept
- Instanziierte Speicherobjekte haben zu jeder Zeit immer einen Besitzer
- Variablen wechseln den Besitzer oder müssen an dessen ausgeliehen (Borrow) werden
- Borrow-Checker
- Prüft ob der Besitz geklärt ist
- Prüft ob eine Variable verändert werden darf, d.h wird an verschiedene Stellen zeitgleich darauf zugegeriffen und gar verändert, führt dies zu einem Kompilierfehler
- dies bricht an vielen Stellen mit den gewohnten Konzepten von anderen Programmiersprachen (Singleton)
- Lifetime Checker
- Analyse des Scopes, der enthaltenen Variablen und deren Referenzen
- Die Lebenszeit von Speicherobjekten muss zu jeder Zeit bekannt sein
- Die Lebenszeit eines Speicherobjekts endet in der Regel mit dem Verlassen des Scopes
Installation
- Vollständige Installation übr rustup.rs
- Alternativ kann auch der Rust Playground verwendet werden
Lust auf mehr Rust
Grundlagen
- Erlernung der einfachen Handhabung von Rust Projekten mit Cargo
- Kenntnisse über
- einfachen Datentypen
- Funktionen
- Kontrollfluß
Cargo
Zuerst erstellen wir ein Standardprojekt für eine Applikation
cargo new my-simple-project
cargo erstellt uns dann folgende Dateien
- Cargo.toml # Projektbeschreibung mit all seinen Abhängigkeiten
- src/main.rs # Unser erstes Programm
Dann können wir das Projekt auch sofort bauen
cd my-simple-project
cargo build
und auch starten
cargo run
Das Result sollte dann so aussehen
Hello, world!
Die optimierte Variante wird wie folgt erstellt:
cargo build --release
Die Cargo.toml
Die Cargo.toml verwaltet grundsätzliche Dinge zum Projekt, wie:
- Projektdefintion selbst
- Name
- Beschreibung
- Version
- Rust-Version
- Links zum Repository
- Veröffentlichungsregeln
- Paketabhängigkeiten
- Versionen
- Features
- Lokale Quellverzeichnisse / Git Repositories
- Unterprojekte
Für unser erstes Projekt ist dies noch recht klein:
[package]
name = "my-simple-project"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
Wird ein Build erzeugt, werden die abhängigen crate Versionen in der Cargo.lock festgehalten. Es wird generell empfohlen Versionen zu pinnen.
Die Cargo.toml zu diesem Projekt ist dann etwas komplexer.
Die komplette Referenz, könnt ihr auf der cargo-Dokumentationseite finden.
Cargo für Rust Programme
cargo kann nicht nur verwendet werden, um Rust Projekte zu erstellen und zu bauen. Es kann auch dazu verwendet werden, um Applikationen zu installieren.
Beispielsweise um dieses Tutorial wurde mdbook verwendet, was mittels
cargo install mdbook
installiert wurde. Die fertige Anwendung wird dann standardmäßig in ~/.cargo/bin abgelegt.
Einfache Datentypen, Variablen und Funktionen
Variablendfinition
- Variablen sind standardmäßig unveränderbar und müssen mit dem Keyword
mutmarkiert werden - An vielen Stellen hilft es die Variable einfach neu zu definieren
fn main() { let a = 1; // Hier scheitert der Kompiler a = 2; // mut definiert eine Variable als veränderbar let mut b = 1; // damit ist dies möglich b = 2; // Eine Neudefinition ist ebenfalls möglich let c = 1; let c = 2; println!("a={}", a); println!("b={}", b); println!("c={}", c); }
Typendeklaration und -inferenz
- Viele Typen werden automatisch erschloßen
- Für ganze Zahlen wird automatisch ein 32-Bit signed Integer angenommen
- Für rationale Zahlen wird eine 32-Bit Fließkommazahl angenommen
- Explizite Typisierung meist nicht notwendig, da der Kompiler die Typen erschließen kann
fn main() { let integer: u16 = 1; let float: f32 = 1.23; let boolean: bool = false; let a_char: char = 'X'; let void: () = (); let tuple: (u8, char) = (1, 'a'); let simple_string: &str = "a char array"; // Standardausgaben der einfachen Datentypen println!("integer = {}", integer); println!("float = {}", float); println!("char = {}", a_char); println!("bool = {}", boolean); println!("simple string = {}", simple_string); // Ein komplexer String let complex_string: String = String::from("a more complex string"); println!("complex_string = {}", complex_string); // Für manche ist die Ausgabe nicht verfügbar, dafür aber eine Debug-Ausgabe println!("void = {:?}", void); println!("tuple = {:?}", tuple); let a_huge_integer: i128 = 1_000_000_000_000_000_000_000_000_000_000; let a_signed_integer = -1; let a_precise_float: f64 = 1.055736284329874932749329479237492374; println!("a_huge_integer = {:?}", a_huge_integer); println!("a_signed_integer = {:?}", a_signed_integer); println!("a_precise_float = {:?}", a_precise_float); }
- Verschiede größen sind vordefiniert wie unsigned/signed Integer für 8,16,32,64,128 oder Gleitkommatype für 32,64 Bit.
Funktionen
- Funktionen müssen typisiert werden
- die letzte Zeile gibt den Funktionswert zurück
- ist der letzte Zeile durch ein Semikolon beendet, ist der Typ leer
fn void_func() -> () { println!("void function"); } fn another_void_func(value: &str) { println!("another void function: {}", value); } fn all_together(value: &str) -> usize { value.len() } fn main() { void_func(); another_void_func("Hello CLT"); println!("String length {}", all_together("Hello CLT")); }
- Lambdas sind ebenfalls möglich
fn main() { let lambda = |x, y| x*y; println!("Lambda result {}", lambda(3, 4)); }
Typenkonvertierung
- Variablen können explizit typisiert werden
- Der Kompiler gibt ein Fehler aus, wenn
- ein Typ nicht bekannt ist
- mehrere mögliche Interpretationen gibt
- der Quell- und Ziel Typ nicht zusammen passen
- Gerade um den Kompiler bei der richtigen Implementierungswahl zu helfen, ist es of einfacher eine Variablendefintion zu Typisierungen
- Vielen Konvertieren können auch über Traits umgesetzt werden, dazu später mehr
fn main() { // Explizite Definition von Variablentypen let unsigned_16bit_integer = 1_u16; // Am Wert let signed_16bit_integer: i16 = -1; // An der Variablendeklaration // Funktionsdefition mit den spezifischen Datyentypen fn mul(a: i32, b: i32) -> i32 { a * b // ein expliztes return ist nicht notwendig } // Funktionsdefintion mit leeren Rückgabetyp, dies ist äquivalent // fn do_useless_add(a: i32, b: i32) -> () { ... } fn do_useless_add(a: i32, b: i32) { // Ohne Semikolon würde diese Zeile ein Fehler erzeugen a * b; } let a_result = mul(signed_16bit_integer as i32, unsigned_16bit_integer as i32); println!("Result of {} * {} = {}", signed_16bit_integer, unsigned_16bit_integer, a_result); }
Referenzen
- Die meist verbreiteste Referenz dürfte die zu einem einfachen String sein
- Referenzen müssen verwendet werden, wo keine explizte Datentypgröße vorhanden ist bspw. bei generische Datentypen
- Für referenzierte Werte gelten ebenfalls die Regeln für Veränderlichkeit, d.h. per Standard sind die referenzierte Daten unveränderbar
fn main() { let a_string: &str = "Hello world"; println!("a_string={}", a_string); let a_u32 = 2022; let ref_to_u32: &u32 = &a_u32; // Zugriff auf den Wert mittels Dereferenzierung println!("ref_to_u32={}", *ref_to_u32); // Integer ist veränderlich let mut a_mut_u32 = 2022; // Die Referenz selbst nicht, aber der referenzierte Wert let ref_to_mut_u32 = &mut a_mut_u32; // Damit kann auch der referenzierte Wert verändert werden *ref_to_mut_u32 = 42; println!("ref_to_mut_u32={}", *ref_to_mut_u32); // Referenzen an sich dürfen ebenfalls verändert werden let mut mut_ref_to_u32 = &1; mut_ref_to_u32 = &2; println!("mut_ref_to_u32={}", *mut_ref_to_u32); }
- Wird eine Referenz genutzt, wird automatisch der Borrow Checker involviert und es stellt sich die Frage des Ownerships
Arrays
- Arrays werden als
slicesbezeichnet - Rust folgt bei Zeichenketten der C++ Definition, es gibt einfache Zeichenketten ähnlich char-Arrays und komplexere Strings
- Hinweis: einfache Strings und Arrays können je nach Definition eine unbekannte Größe haben und müssen als Referenz behandelt werden
fn main() { let integer_array: [u8; 3] = [1u8, 2, 3]; // Auch hier können wir nur eine Debug-Ausgabe durchführen println!("integer_array = {:?}", integer_array); println!("2nd element of integer_array = {}", integer_array[1]); }
- Durch die statische Größe, kann der Kompiler auch Range Checks vorab durchführen
- Ein Zugriff außerhalb des Bereichs führt zu einem Kompilierfehler
fn main() { let integer_array: [u8; 3] = [1u8, 2, 3]; integer_array[3]; }
Selbstdefinierte Datentypen
- Datentypen werden über das Schlüsselwort
structdefiniert - Datentypen können auch keinerlei Inhalt haben
- Wrapper für die Kappselung von anderen Datentypen
- Implementierungen für
structs - Mittels Macros können verschiedene Eigenschaften hinzugefügt werden, bspw.
- Kopierverhalten
- Bereitstellung einer Debug-Darstellung
- Sonstige Erweiterungen für bspw. Datenbankeigenschaften
#[derive(Debug)] struct OneValue { value: u32, } #[derive(Debug)] struct Empty { } #[derive(Debug)] struct Wrapper(u32); impl OneValue { fn new() -> Self { OneValue { value: 0, } } fn do_something(&self) { println!("My value is {}", self.value); } fn change_something(&mut self) { self.value += 1; } } impl Empty { fn do_something_static() { println!("A voice from the void"); } } fn main() { let mut one_value = OneValue::new(); one_value.do_something(); one_value.change_something(); let empty = Empty { }; Empty::do_something_static(); let wrapped = Wrapper (1); // Ausgabe über Debug-Macro println!("one_value = {:?}", one_value); println!("empty = {:?}", empty); println!("wrapped = {:?}", wrapped); }
- Enums orienteren sich an der C-Notation
- Enums können aber mit weiteren Strukturen erweitert werden
- Auch Enums können mit Macros erweitert werden
// Unterstützung für Gleichheits-Operator #[derive(Debug,PartialEq)] enum Status { Ok, GenericError(String), ApplicationError { prio: u32, cause: String }, } impl Status { fn am_i_ok(&self) -> bool { *self == Status::Ok } } enum IpAddr { V4(u8, u8, u8, u8), V6(String), } fn main() { let result: Status = Status::Ok; println!("Ok {:?}", result); println!("Ok? {:?}", result.am_i_ok()); let result = Status::GenericError(String::from("Something went wrong")); println!("{:?}", result); let result = Status::ApplicationError { prio: 1, cause: String::from("Something more specific") }; println!("{:?}", result); }
Kontrollfluß nund Funktionen
If/Then/Else
fn main() { if true { // wird ausgeführt } else { // wird nicht ausgeführt } let i = 3; if i == 0 { // ... } else if i == 1 { // ... } else { // ... } }
Schleife
- Einfache Schleife
fn main() { let mut i = 0; loop { if i > 100 { break; } i += 1; } }
- For-Schleife
fn main() { for i in 0..5 { println!("i = {}", i); } }
Match-Operator
fn main() { let num = 1; let string: &str = match num { 1 => "One", 2 => "Two", 3 => "Three", _ => "Too lazy", }; println!("Number {}", string); }
Elvis-Operator
- Fehlerbehandling ist oft viel Schreibarbeit
- Der Elvis-Operator kann Vieles vereinfachen
- Wird ein fehlerhafter oder leerer Wert zurückgegeben
fn do_something_error_prone(will_fail: bool) -> Result<String, String> { match will_fail { false => Ok("Ok".to_string()), true => Err("Ups".to_string()), } } fn main() -> Result<(), String> { let result = do_something_error_prone(false)?; println!("It's ok? {}", result); let result = do_something_error_prone(false)?; println!("It's also ok? {}", result); Ok(()) }
- Die Behandlung von optionalen Werten kann mitunter auch viel Schreibarbeit sein
- Optionale Werte
fn be_positive(num: i32) -> Option<i32> { if num >= 0 { Some(num) } else { None } } fn check_number(num: i32) -> Option<i32> { let result: i32 = be_positive(num)?; println!("Number {} is positive", result); Some(result) } fn main() { println!("Call with 1: {:?}", check_number(1)); println!("Call with 2: {:?}", check_number(2)); println!("Call with -1: {:?}", check_number(-1)); }
Don't Panic - but Panic
- Es werden verschiede Konstrukte angeboten, um das Program sofort zu beenden
panic!Makro- Für Ergebnis Typen die Funktion
expect
fn main() { panic!("Something really terrible happens"); }
fn main() { let open_result: Result<String, String> = Ok(String::from("It's ok")); let result: String = open_result.expect("An ok"); println!("Ok? {:?}", result); let open_result: Result<String, String> = Err(String::from("It's not ok")); let result = open_result.expect("An ok"); // Wird nicht mehr ausgeführt println!("Ok? {:?}", result); }
Aufgabe: Rechner
Ziel
- Schreibt einen einfachen Rechner
- Operand
aist eine Zahl - Operator
opist ein String - Das Ergebnis wird ausgerechnet und ausgegeben
Hilfen
Folgende Datei könnt ihr als Ausgangsgrundlage nutzen
enum Operation { Add, // TODO: Operation hinzufügen } /// Führt eine Operation aus fn operate(a: i32, op: Operation, b: i32) -> Result<i32, String> { // TODO: Operation implementieren Err("Not implemented".to_string()) } /// Wandelt ein Operations-String in eine Operation um fn map_string_to_operation(input: &str) -> Result<Operation, String> { match input { "+" => Ok(Operation::Add), // TODO: Operation ergänzen _ => Err("Operation not implemented".to_string()), } } fn main() -> Result<(), String> { let a = 1; let op = "-"; let b = 2; println!("Result: {}", operate(a, map_string_to_operation(op)?, b)?); Ok(()) }
Musterlösung
Ownership-Konzept
- Verständnis über den Umgang mit Speicher
- Konzept von Ownership, Borrow, Lifetimes zu verstehen
Speicherverwaltung
Clone and Copy
- Standardmäßig sind bei eigensdefinierten Datentypen keine Kopierfunktionen vorhanden
- Für diesen Zweck definiert Rust zwei Traits
Copy: Passiert implizit und führt eine bitweise Kopie der Variable durchClone: Muss explizt angefordert werden und k Bitweises kopieren erzeugt eine vollständige Kopie- Jedes Objekt, welches Copy implementiert, implementiert auch Clone
- Aber nicht jedes Objekt, welches Clone implementiert, implementiert auch Copy
structskönnen beispielsweise nicht duplizierbare Bestandteile haben- In den meisten Fällen reicht jedoch ein Standardverhalten vorzuschreiben
- Für diesen Zwecks gibt es den
Clone-Trait - Um automatisch eine gültige Implementierung zu nutzen, kann das
derive-Makro mitCloneverwendet werden
#[derive(Clone, Debug)] struct CloneableItem { value: u32, } #[derive(Clone, Copy, Debug)] struct CopyableItem { value: u32, } fn main() { let item_cloneable = CloneableItem { value: 1 }; let item_cloned = item_cloneable.clone(); let item_copyable = CopyableItem { value: 2 }; let item_copied1 = item_copyable; let item_copied2 = item_copyable; println!("Pointer:"); println!("Cloneable {:p}", &item_cloneable); println!("Cloned {:p}", &item_cloned); println!("Copyable {:p}", &item_copyable); println!("Copied 1st {:p}", &item_copied1); println!("Copied 2nd {:p}", &item_copied2); }
Speicherobjekte auf dem Heap
- Nicht immer ist es möglich Speicher zu auf dem Stack zu verwalten
- Speicherbereich kann zu begrenzt sein
- Instanzen müssen an vielen Stellen referenziert und verändert werden
- Für diesen Zweck gibt es den Box-Typ
- Bei der Instanziierung wird ein Speicherbereich auf dem Heap allokiert
- Wird die
Boxnicht mehr gebraucht, dann wird der Bereich wieder freigegeben
fn main() { // Object auf dem Heap anlegen let heap_var: Box<[u32]> = Box::new([42u32; 4096]); // Dereferenzierung für einen Zugriff println!("heap_var = {}", heap_var[0]); }
Dynamische Listen
- Gerade bei veränderlichen Listen sind die statischen Arrays hinderlich
- Hierfür kann der generische Datentyp
Vecgenutzt werden
fn main() { let integer_array = vec![1, 2, 3]; // explizt typisiert let integer_array: Vec<i32> = vec![1, 2, 3]; // Für die Veränderung einer Liste, muss diese wieder mit `mut` gekennzeichnet werden let mut list = vec![]; list.push(1); list.push(2); println!("list = {:?}", list); }
Ownership
Das grundsätzliche Problem
- Besitz bedeutet, wer allokiert den Speicher und darf eventuell den Speicher verändern
- Ist dies nicht eindeutig geklärt, wird der Kompiler einen Fehler werfen
fn main() { let mut owned = 1; let next_owner = &owned; println!("owned = {}", owned); // Leses ist Ok owned = 2; // Schreiben schlägt fehl println!("next_owner = {}", next_owner); // next_owner ist der Besitzer }
- Speicherbereiche können ausgeborgt werden
- Ist das Verhältnis, wer welchen Bereich ausgeborgt hat und darauf zugreift ungeklärt, wird der Kompiler einen Fehler werfen
fn main() { let owned = 1; let borrowed = &owned; println!("owner = {}", owned); println!("borrowed = {}", borrowed); }
- Können Speicherbereiche verändert werden und werden sie ausgeborgt, gibt es auch Probleme
fn main() { let mut owned = 1; let borrowed = &owned; println!("owner = {}", owned); owned += 1; // Hier streikt der Kompiler println!("borrowed = {}", borrowed); }
- Auch das explizite Ausleihen eine veränderbaren referenzierten Wert, wird nicht funktionieren
fn main() { let mut owned = 1; let borrowed1 = &mut owned; let borrowed2 = &mut owned; println!("owner = {}", borrowed1); *borrowed2 += 1; println!("borrowed = {}", borrowed2); }
Das unmögliche, möglich machen - veränderliche geteilte Referenzen
- Normalerweise würde der Kompiler veränderbaren geteilten Referenzen streiken
- Gerade bei selbstreferenziellen Datenstrukturen (Graphen) kann dies ein Problem sein
- Dennoch ist dies möglich durch die Anwendung von Typen wie
Cell: Teilbarer veränderlicher ContainerRefCell: Referenz zu veränderlichen Container
use std::cell::RefCell; fn main() { let owned = RefCell::new(1); let borrowed1 = owned.clone(); let borrowed2 = owned.clone(); println!("owner = {}", owned.borrow()); println!("borrowed1 = {}", borrowed1.borrow()); *borrowed2.borrow_mut() += 1; // Explizite Veränderlichkeit anfordern println!("borrowed2 = {}", borrowed2.borrow()); }
- Bei multithreaded Anwendungen können diese Typen nicht verwendet werden, allerdings gibt es Alternativen wie:
Channels: Simple Queue mit Sender und EmpfängerMutex: Mutex zum temporären Sperren von Ressourcen
Lifetime
Kurz Auffrischung: Speichermodel
- Ein kurzer Ausflug in die Arbeitsweise des Stacks
- Jeder Variabledeklaration, Funktionsaufruf, etc. belegt normalerweise Speicher auf dem Stack (Optimierung ausgenommen)
- Werden Variablen in einem Scope erzeugt, wird der Stack bis zum Eintritt in dem Scope danach bereinigt
- Der Heap ist ein gesonderter Speicher, von dem Speicherbereiche dynamisch angefordert und freigegeben werden. Eine feste Ordnung wie beim Stack hat dieser nicht

Das Ausleihproblem
- Durch das Ownership/Borrow-Konzept stellt sie die Frage, wie lange Speicherbereiche genutzt werden können
- Gibt es keinen Besitzer mehr und ist der Bereich nicht ausgeliehen, kann der Bereich freigegeben werden
- Rust nutzt keine Garbage Collection und braucht das Wissen über Speichernutzung
fn main() { let mut a; { let b = 1; a = &b; } // b existiert nur im Scope und wird beim Verlassen freigegeben println!("a = {}", *a); }
- Der C-Kompiler würde dies Problem zwar anmerken, das Programm idR. aber übersetzen
- Die Ausführung erzeugt einen Fehler
#include <stdio.h>
static int zero = 0;
int* func() {
int b = 1;
return &b;
}
int main(int argc, char* argv[]) {
int *a = &zero;
a = func();
printf("%i\n", *a);
}
Statische Laufzeit
- Kurzfristige Lösung für viele Probleme mit der Lebenszeit von Objekten
- Kann aber mitunter andere Probleme versachen, da hier ebenfalls wieder mit Referenzen gearbeitet werden muss, wenn die Speicherbereiche eine variable Größe haben sollen
fn main() { let mut a; { static b: i32 = 1; // b ist nun statisch deklariert und überlebt den Scope a = &b; } println!("a = {}", *a); }
Referenzzähler
- Am besten Vergleichbar mit dem
shared_ptrin C++ - bei jedem
clonewird die Referenz erhöht - verlässt die Referenz ihren Scope wird die Referenz heruntergezählt
- Ist die Referenz 0 wird der Bereich freigegeben
use std::rc::Rc; static ONE: i32 = 1; fn main() { let mut a = Rc::new(0); println!("address of a={:p}", a); { let b = Rc::new(ONE); println!("address of b={:p}, address of one={:p}", b, &ONE); a = b.clone(); } println!("address of a={:p} after changing", a); println!("content of a = {}", *a); }
Rcist nicht nicht thread-safe, stattdessen sollteArcverwendet werden
Übungsaufgabe
Ziel
- Modelliert ein Freundschaftsnetzwerk
- Eine
struct Friendsoll lediglich einen namen enthalten - Am Ende soll es möglich sein, eine Dreiecks-Bezeihung zu modellieren
- Bezieherungen zu Freunden sollen mittels Referenzen dargestellt werden
- Über einen Freund kann ich zu nächsten Freund navigieren
Hilfestellung
- Ihr könnt für Listen den Typ
Vec<Friend>verwenden - Dokumentation von
Rc - Dokumentation von
RefCell
#![allow(unused_imports)] #![allow(dead_code)] use std::rc::Rc; use std::cell::RefCell; struct Friend { name: String, // TODO: Liste mit Freunden definieren } impl Friend { fn new(name: &str) -> Self { Friend { name: name.to_string(), // TODO: Liste mit Freunden definieren } } } fn main() { let a = Friend::new("Zero Cool"); let b = Friend::new("Acid Burn"); let c = Friend::new("Cereal Killer"); // TODO: Freundesnetzwerk erstellen }
Musterlösung
Wir abstrahieren uns die Welt, wie sie uns gefällt
- Umgang mit generischen Datentypen und Implementierung
- Verwendung von Traits
- Zero Cost Abstractions kennenlernen
Generics
- Rust übernimmt für Generics ähnliche Konstrukte wie bei C++ oder Java
- Auch hier spielt die Typeninferenz wieder eine Rolle, da die konkreten Typen aus dem Zusammenhang geschlußfolgert werden können
- Konkrete müssen nicht zur Laufzeit instanziiert und dann konvertiert werden
struct MyGenericStruct<T> { items: Vec<T>, } fn main() { let struct_with_u32: MyGenericStruct<u32> = MyGenericStruct { items: vec![], }; let struct_with_u16 = MyGenericStruct::<u16> { items: Vec::new() }; let struct_with_u8 = MyGenericStruct { items: Vec::<u8>::new() }; }
- Generische Typen können konkrete Implementierungen nur für einen Typ besitzen
struct MyGenericStruct<T> { a: T, b: T, } impl MyGenericStruct<i32> { fn sum(&self) -> i32 { self.a + self.b } } fn main() { // Für i32 liegt eine Implementierung vor, u32 Typen können nicht verarbeitet werden MyGenericStruct { a: 1, b: 2 }.sum(); }
- Auch für generische Typen können generische Implementierungen verwendet werden
- Damit er Kompiler dies richtig umsetzen kann, müssen wir ggf. Randbedingungen an unsere Generics stellen, welche Traits umgesetzt werden müssen
struct MyGenericStruct<T> { a: T, b: T, } impl<T> MyGenericStruct<T> where T: std::ops::Add<Output=T>, T: std::marker::Copy { fn sum(&self) -> T { self.a + self.b } } fn main() { MyGenericStruct { a: 1i32, b: 2i32 }.sum(); MyGenericStruct { a: 3u32, b: 4u32 }.sum(); MyGenericStruct { a: 5i8, b: 6i8 }.sum(); MyGenericStruct { a: 7.1, b: 8.2 }.sum(); }
Traits
- Traits definieren ein gemeinsames Verhalten am ehsten Vergleichbar mit Interfaces
- Datentypen implementieren Traits
- Traits können ebenfalls Randbedingungen für Generics sein, um auf notwendige Implementierungen zu verweisen
pub trait Noise { fn noise(&self) -> String; } fn make_some_noise<T>(something: &T) -> String where T: Noise { something.noise() } struct Cat; impl Noise for Cat { fn noise(&self) -> String { "Moew".to_string() } } fn main() { let cat = Cat { }; println!("Cat does {}", cat.noise()); }
Einfach erweitern
- Viele Standardmethoden werden über Implementierung von Traits realisiert
use std::fmt; use std::convert::From; struct Cat { name: String, } struct Dog { name: String, } impl fmt::Display for Cat { fn fmt(&self, formatter: &mut fmt::Formatter) -> fmt::Result { write!(formatter, "A cat named {}", self.name) } } impl fmt::Display for Dog { fn fmt(&self, formatter: &mut fmt::Formatter) -> fmt::Result { write!(formatter, "A dog named {}", self.name) } } impl From<Cat> for Dog { fn from(cat: Cat) -> Self { Dog { name: cat.name } } } fn main() { let cat = Cat { name: "Mitze".to_string(), }; println!("What is it? {}", cat); let dog: Dog = cat.into(); println!("What is it? {}", dog); }
Übungsaufgabe
Ziel
- Ein einfacher String soll in einen Operationstyp umgewandelt werden
- Die Berechnung der Operation soll bei der Darstellung der Operationsdatenstruktur durchgeführt werden
Hilfestellung
- Traits für Rechenoperationen sind in
std::opsdefiniert
use std::convert::From; use std::fmt; #[derive(Debug)] enum OperationType { Add, Sub, Mul, Div, } #[derive(Debug)] struct Operation<T> { a: T, b: T, op: OperationType, } impl<T> fmt::Display for Operation<T> where T: std::marker::Copy, T: std::fmt::Display, // TODO: weitere Trait-Anforderungen definieren { fn fmt(&self, formatter: &mut fmt::Formatter) -> fmt::Result { write!(formatter, "{}", "Not implemented") } } impl From<&str> for OperationType { fn from(input: &str) -> Self { match input { // TODO: Mapping implementieren _ => OperationType::Add, } } } fn main() -> Result<(), String> { let op = Operation { a: 1, op: "+".into(), b: 2}; println!("Result: {}", op); Ok(()) }
Musterlösung
Strukturierung, Dokumentation, Tests
- Struktuierung und Aufteilung von Code
- Kenntnis von den Testmöglichkeiten
- Integrierte Dokumentation
Crates, Module, Sichtbarkeit
- Jedes Cargo Projekt ist automatisch ein
crate
struct MyStruct; fn main() { let a = crate::MyStruct; }
- Applikationen, wenn nicht anders definiert, nutzen meist die Datei
main.rs - Libraries, nutzen
lib.rs
Module und Sichtbarkeit
- Crates können Applikationen oder Libraries für Funktionen, Datenstrukturen, Makros, ... sein
- Module bilden Namensräume die ganze oder nur Teile daraus über
useimportiert werden können - Nur auf Datentypen, Funktionen und Module, die als
pubdeklariert sind, kann von außen zugegriffen werden
mod my_module { pub struct MyPublicStruct { } impl MyPublicStruct { pub fn public_func(&self) { } fn private_func() { } } struct MyPrivateStruct { } impl MyPrivateStruct { fn func(&self) { } } } use my_module::{MyPublicStruct}; fn main() { MyPublicStruct { }.public_func(); // alternativ, kann aber Probleme mit Traits machen my_module::MyPublicStruct { }.public_func(); }
- Module können auch ohne weiteres in andere Dateien ausgelagert werden
- Hierfür muss nur der Modulname deklariert werden und der Kompiler bezieht die Datei mit ein
pub mod my_module;
use my_module::{MyPublicStruct};
fn main() {
MyPublicStruct { };
}
// my_module.rs oder my_module/mod.rs
pub struct MyPublicStruct { }
Testing
Unittests
- Integriertes Testkonzept
cargo testführt die Tests aus- Tests müssen nur mit den Makro
#[test]markiert werden - Framework erweitern die Testfunktionen bspw. um asynchrone Funktionen, sequentielle Ausführung etc
- Tests werden gerne in getrennte Testmodule verlagert
- Feature
testwird bei der Ausführung aktiviert, mit dem Makro#[cfg(test)]wird dann nur für den Test der entsprechende Code kompiliert
fn main() { } pub fn add_signed_int16(a: i16, b: i16) -> i16 { a + b } #[cfg(test)] mod test { use super::*; #[test] fn test_signed_add() { assert_eq!(3, add_signed_int16(1, 2)); assert_eq!(-1, add_signed_int16(2, -3)); } }
- Auch testbar über den Rust Playground
Benchmarks
- Cargo intergriert ebenfalls eine Benchmark Suite
- Wird über
cargo benchaufgerufen
Dokumentation
- Vollintegrierte Dokumentation
- Erstellung mit
cargo doc - Paketdokumentation können auf docs.rs gefunden werden
- Dokumentation von alle genutzten
crateswerden standardmäßig inkludiert - Rust Code, der dokumentiert wird, wird für Libraries automatisch getest
/// Gibt das Ergebnis einer vorzeichenbehafteten Addition mit einem 16-Bit Integer zurück /// /// # Argumente /// /// * `a` - 1. Summand /// * `b` - 2. Summand /// /// # Beispiele /// /// ```rust /// add_signed_int16(1, 2); /// ``` fn add_signed_int16(a: i16, b: i16) -> i16 { a + b } fn main() { }
mdbook
-
Dieser Workshop wurde mittels mdbook
-
Alle Code läuft dabei durch einen Tests, wenn nicht besonders markiert
-
Nutzt Standard Markdown mit ein paar Erweiterungen
-
Installtion
cargo install mdbook
- Lokal anschauen
mdbook serve
- HTML erzeugen
mdbook build
- Testen
mdbook test
Asynchrone Verarbeitung
- Selbst heutige Mikrokontroller sind Mehrprozessorsystem
- Die parallele Ausführung von Code spart oft nicht nur Zeit sondern auch Energie
- An vielen Stellen kann auch ein Programm auf Daten warten, d.h. Aufgaben können aufgeschoben werden, wenn sie notwendig sind
- Rust nutzt hier für die
async/awaitSyntax- eine Funktion ist
asynchron - auf der Ergebnis einer asynchronen Funkten muss gewartet werden (
await)
- eine Funktion ist
- In der Vergangenheit wurden nebenläufige Funktionen oft mit Threads des Betriebssystems umgesetzt
- relativ schwergewichtig sowohl für CPU als auch Arbeitsspeicher
- fast überall einsetzbar
- Durch die Integration in der Sprache, kann der Kompiler besser darüber entscheiden
- asynchrone Funktionen können Rust in einer Runtime ausgeführt werden
- Die Runtime entscheidet, wann welcher Funktion ausgeführt wird und verwaltet die Ausführung über mehrere Threads
- Eine klassische Ausführung über Threads mit Rusts selbst ist möglich
- Bekannte Vertreter für Runtimes sind
tokioundasync-std
- async Traits werden zurzeit nicht von Rust nativ unterstützt, dafür kann aber das async-trait crate genutzt werden
Probleme von Nebenläufigkeit
Verwendung von gemeinsamen Speicher
- Nur lesen ist einfach
- Wird Speicher verändert müssen die Zugriffe verwaltet werden
- Verwaltung kostet Leistung
Lösung:
- Um dies besser zu implementiert, kommt uns der Borrow-Checker zu Hilfe
- Explizter Ausdrücke für veränderliche Speicherbereihe
- Borrow-Konzept markiert Bereiche die veränderlich/unveränderlich sind
- Shared-Nothing-Konzepte sollen bevorzugt werden, hierfür können bspw.
Channelverwendet werden, um zwischen Funktionen Speicherbereiche zu "versenden" - Synchronisierungsobjekte wie
Mutexoder Verwendung von Objekten, dieSendundSyncTraits implementieren
Lebenszeit von Speicher
- Solange Speicher von Funktionen nur auf dem Stack stattfindet ist es einfacher
- Speicherbereiche müssen allokiert werden und ggf. ausgetauscht werden
- Mehrere getrennte Funktionen greifen unabhängig auf Speicher zu
Lösung:
- Referenzzähler für eine asynchrone Verarbeitung, da Nutzung von Objekten nicht mehr im Voraus planbar ist
- statische Lebenszeit für Objekte
Beispiel
use std::sync::mpsc;
use std::sync::mpsc::{Receiver, Sender};
use tokio::task;
use tokio::time::{sleep, Duration};
/// Produziert Werte sendet sie über den Channel
async fn async_producer(tx: Sender<u32>, number: u32) {
loop {
let value: u32 = rand::random::<u32>() % 1000;
println!("{:02}: Sende {}", number, value);
let res = tx.send(value);
if res.is_err() {
break;
}
let delay = value + 1000u32;
sleep(Duration::from_millis(delay.into())).await;
}
}
/// Konsumiert die Werte aus dem Channel. Nach `count` Werten wird die Ausführung beendet
async fn async_consumer(rx: Receiver<u32>, count: u32) {
for _ in 0..count {
let value = rx.recv().unwrap();
println!("Empfangen: {}", value);
}
}
/// Ausführung in Tokio Runtime.
///
/// ```
/// let rt = tokio::runtime::Runtime::new().unwrap();
/// rt.block_on(async {
/// // async code
/// });
/// ```
#[tokio::main]
async fn main() {
let (tx, rx): (Sender<u32>, Receiver<u32>) = mpsc::channel();
for num in 0..7 {
task::spawn(async_producer(tx.clone(), num.clone()));
}
task::spawn(async_consumer(rx, 10)).await.unwrap();
}
Demo Webservice
Ziel
- Einfacher Service, der uns eine REST-artige Schnittstelle anbietet
- Anlegen eines Wertes
- Verändern eines Wertes
- Löschen eines Wertes
- Umsetzung mit
rocket
- Datenbank soll unsere Daten halten
- Zur Vereinfachung SQLite
- Daten werden nur im Speicher gehalten
- Umsetzung mit
sqlx
Vorgehen
- Erstellen neues crate mit
cargo
cargo new webservice
- Abhängigkeiten in der Cargo.toml definieren
[package]
name = "webservice"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
rocket = { version = "0.5.0-rc.1", features = ["json"] }
sqlx = { version = "0.5", features = ["sqlite", "runtime-tokio-native-tls", "uuid", "chrono"] }
uuid = { version = "0.8.2", features = ["serde", "v4"] }
async-trait = "0.1.52"
tokio = "*"
serde = "*"
serde_json = "*"
serial_test = "0.6.0"
- Rumpffunktionen für
rocketanlegen
#[macro_use] extern crate rocket; #[get("/")] fn index() -> &'static str { "Hallo CLT 2022" } fn build_server() -> rocket::Rocket<rocket::Build> { rocket::build() .mount("/", routes![index]) } #[rocket::main] async fn main() { build_server() .launch() .await .unwrap(); } #[cfg(test)] mod test { }